有无发财机会
Finally 怎么拖到融资之后
现在都人均1m了吗?
有没有懂的家人们说下几年后有可能爆炸到10m甚至100m吗?
好像国产没有全部 1m?我记得 GLM 5 不是,不知道 5.1 是不是来着
gpt5.5暂时安全?
Mimo 是1M
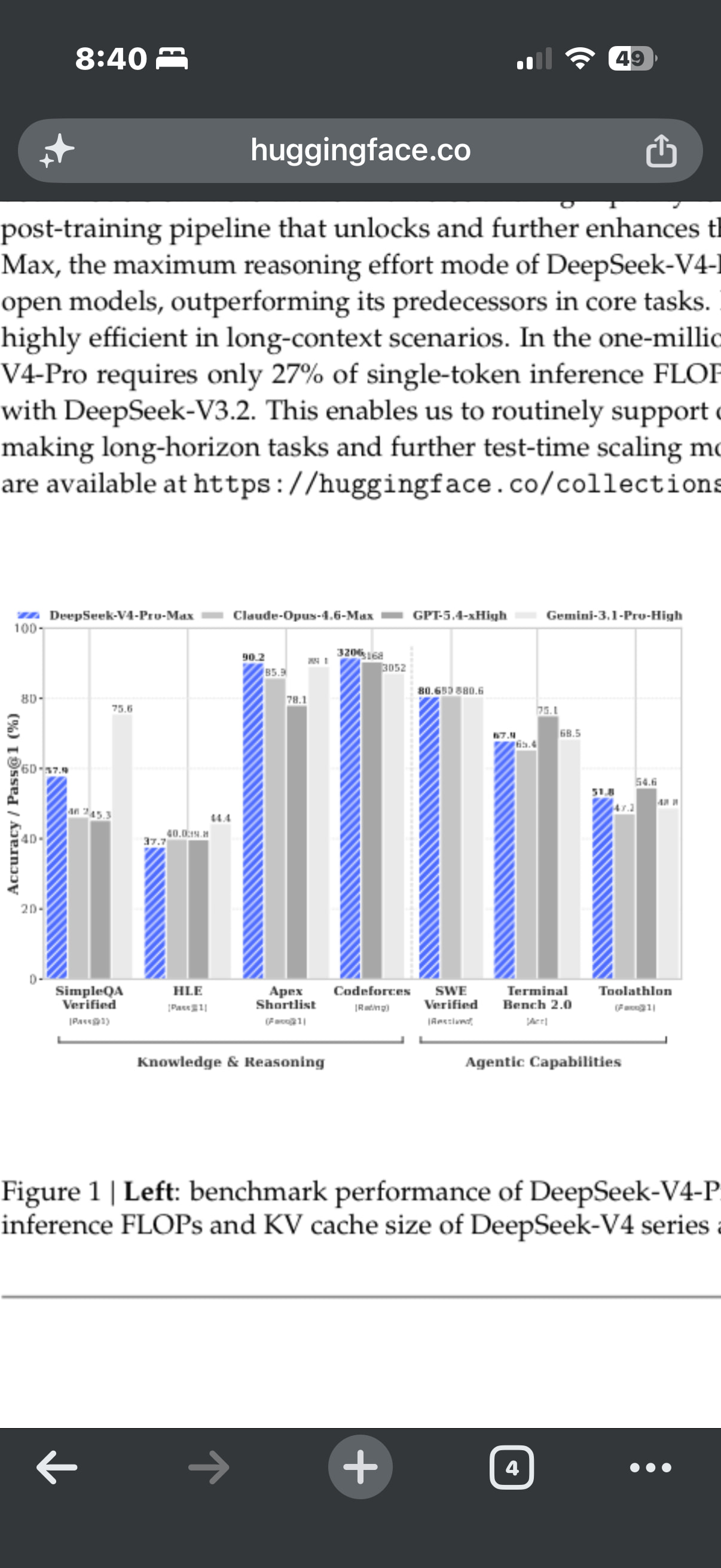
感觉deepseek和国内开源模型真是我等转行AI人的活菩萨。。
qwen 也是,忘了 minimax 是不是了
有点失望,和frontier略有一点差距。本来以为架构上的优势可以体现到下游
| Benchmark | DeepSeek-V4-Flash Non / High / Max | Qwen3.6-27B | 简评 |
|---|---|---|---|
| MMLU-Pro | 83.0 / 86.4 / 86.2 | 86.2 | 基本打平,DS High 略高 |
| GPQA Diamond | 71.2 / 87.4 / 88.1 | 87.8 | DS Max 略高,Qwen 比 DS High 略高 |
| HLE | 8.1 / 29.4 / 34.8 | 24.0 | DS High/Max 明显更强 |
| LiveCodeBench | 55.2 / 88.4 / 91.6 | 83.9 | DS High/Max 更强 |
| HMMT Feb 26 | 40.8 / 91.9 / 94.8 | 84.3 | DS thinking 模式大幅领先 |
| IMOAnswerBench | 41.9 / 85.1 / 88.4 | 80.8 | DS High/Max 更强 |
| SWE-bench Verified | 73.7 / 78.6 / 79.0 | 77.2 | DS High/Max 略强 |
| SWE-bench Pro | 49.1 / 52.3 / 52.6 | 53.5 | Qwen 略强 |
| SWE-bench Multilingual | 69.7 / 70.2 / 73.3 | 71.3 | DS Max 更强,Qwen 强于 DS High |
| Terminal-Bench 2.0 | 49.1 / 56.6 / 56.9 | 59.3 | Qwen 更强 |
用 codex browser use 比较了下,本地跑的话,v4 flash 和Qwen 3.6 27B 看来差不多。
v4 flash moe适合 Mac 大内存
Qwen 3.6 27B dense 适合显卡跑
你看qwen deepseek kimi训练殖人训练得多好,看到国产开放权重大模型就喊蒸馏
v4 flash 284B的参数量,Mac studio跑得要512的unified memory。。M5ultra 512G估计得1w5了吧
是华为 infra 训练出来的吗
看看量化后有多大吧,2bit 128G ,4Bit 256G 应该能跑
想赶紧体验一下
迭代速度是真的猛 感觉刚把V3玩明白
V4接入龙虾以后,感觉会更嗨,opus 4.6不让用订阅制以后,就没啥牛逼的模型了